
Security-informed AI Ethics Framework
Bridging the chasm between cybersecurity and ethics...

Executive Summary
When asked, most cybersecurity practitioners agree that cybersecurity and ethics are related. They are right. But the reality is different on the ground. Cybersecurity practitioners do not regard ethics as a practical discipline, but as a high-level philosophical concept. Similarly, while they are proficient in AI governance, ethics professionals treat cybersecurity as a pure technical domain. Many, including the OECD, disagree. OECD’s value-based AI principles directly include security as one of the principles. In addition, cybersecurity enables other ethical principles, like privacy, accountability, and fairness. This undeniably strong relationship between cybersecurity and ethics makes it possible to repurpose tried and tested cybersecurity concepts in service of ethics. The Security-informed AI Ethics Framework (SAIEF) exploits this synergy and provides organizations, whether makers or users of AI systems, a suite of Security-informed Ethical Controls (SECs) and a methodology to implement them in order to design, develop and deploy ethical AI systems. These SECs are:
Ethics Governance, Risk and Compliance (EGRC)
Ethical Threat Modeling
Ethical-by-Design
Multi-layered Ethical Safeguards
Zero Trust on Ethical Values
Minimum Opacity Principle
Continuous Monitoring and Response
Each SEC is described in detail and a list of controls they consist of. There are certainly more security concepts that can be turned into a SEC to extend SAIEF. Structured along the phases of the AI engineering lifecycle, SAIEF can be implemented in three steps that spans from the pre-engineering phase to post-deployment.
To demonstrate the practical value of SAIEF, it was applied to a well-known case study of Optum’s Impact Pro algorithmic bias. It is shown that had SAIEF been implemented at Optum, the outcome would have been a fairer model with a reduced likelihood of bias by detecting and fixing it early.
In addition, two sample tools are provided to practitioners in implementing SAIEF. These are the Ethical Threat Modeling Worksheet and the Multi-Layered Ethical Safeguards Implementation Guide.
SAIEF busts the myth that ethics is this soft and squishy thing that has a little practical implementation. It also shows that the large overlap between cybersecurity and ethics allows repurposing of the proven cybersecurity concepts to detect and prevent ethics violations. SAIEF bridges the gap between cybersecurity and ethics, and invites cybersecurity practitioners to increase their impact by contributing to AI ethics.
Introduction
While they are intimately related, there seems to be a chasm between cybersecurity and ethics that needs to be bridged. This project aims to do that. Although they have a general awareness that the confidentiality, integrity, and availability of data contributes to human wellbeing, especially by making digital privacy possible, most cybersecurity practitioners regard ethics as an abstract and squishy concept that narrowly overlaps with cybersecurity. Similarly, ethics and specifically technology or AI ethics professionals treat cybersecurity as a purely technical domain. As a result, cybersecurity and ethics are treated as separate domains robbing each other of, instead of borrowing, invaluable concepts and practices that could be mutually beneficial to advance both disciplines. In fact, ethics and security feed off of each other: There is no ethics without cybersecurity and there is no cybersecurity without ethics. For example, without protecting the integrity of the training data, it can be open to tampering and introduction of datasets violating ethical values. Similarly, if an AI system violates ethical values, such as providing racist outputs or unfairly denying users access to services with no explanation, the system will generate hatred towards itself, and as a result, it could be a target of increased cyberattacks (it would also increase societal safety risks, but that is out of scope for this work). The goals of this work are:
Establish the relationship between cybersecurity and ethics
Offer an an ethical framework that borrows concepts from cybersecurity: Security-Informed AI Ethics Framework (SAIEF)
Publish blog posts and videos to raise awareness within both the Cybersecurity and Ethics communities
Provide tools to implement the SAIEF framework
Ethical AI considerations
This framework was developed by considering the Organisation for Economic Co-operation and Development’s (OECD) 5 value-based AI principles, which are:
Inclusive growth, sustainable development and well-being
Human rights and democratic values, including fairness and privacy
Transparency and explainability
Robustness, security and safety
Accountability
One of the considerations developing the framework was to identify if there were any Security-informed Ethical Controls (SEC) that were exclusively applicable to a specific principle. It was found, however, that the selected SECs had an impact on all the principles at varying degrees.Therefore, the framework does not map the SECs to different AI principles, and it lumps all these principles under ethical AI.
The relationship between cybersecurity and ethics
Cybersecurity and ethics are closely related in three ways. First, security (robustness, security and safety) is one of the five OECD AI principles. Also, ethical concepts find place and use in cybersecurity, such as ethical hacking and ethical vulnerability disclosure. Second, cybersecurity can be an enabler to establish the other principles in technologies like AI. For example, keeping digital private data confidential allows for privacy. Third, there are many concepts in cybersecurity that lend themselves to be used to further ethical values in technologies in general, and specifically in AI. For example, the well-established concept of secure-by design has its twin in technology ethics: ethical-by-design. Lastly, the mindset and traits of security practitioners are highly transferable to ethics. For example, security practitioners work to protect complex systems, like organizations, and this experience can be invaluable in working with complex systems and concepts such as AI and ethics.
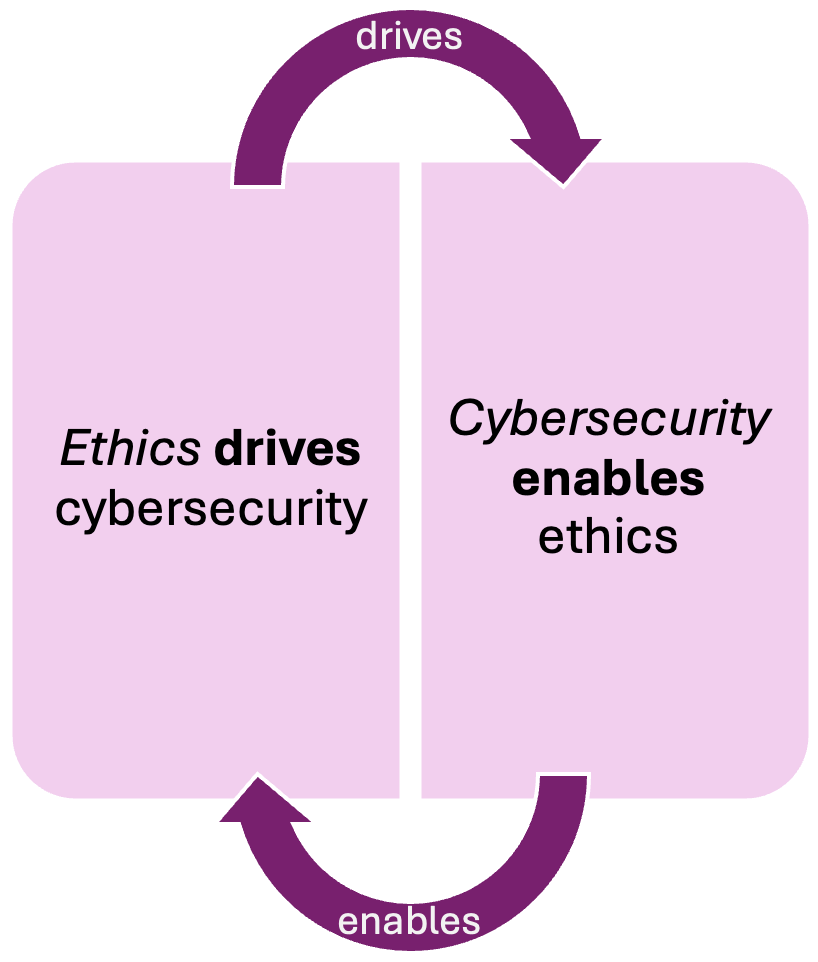
It is pretty clear that cybersecurity and ethics significantly overlap and the SAIEF framework makes ethics more practical and applicable for those who think of ethics as more of a theoretical concept.
Security-Informed AI Ethics Framework (SAIEF)
An Ethical AI Approach Through Cybersecurity Principles
Framework overview and architecture
The Security-Informed AI Ethics Framework (SAIEF) translates proven cybersecurity concepts into systematic ethical safeguards for AI systems. By applying a security mindset, SAIEF creates layered and proactive defenses against ethical harms rather than reactive compliance.
The benefits of the SECs would have a positive impact on all OECD value-based AI principles in varying degrees since these values are highly interrelated (i.e. ethical threat modeling would identify threats to fairness as well as to accountability). As a result, SAIEF does not attempt to map the SECs to different AI principles.
Like most such frameworks, executive leadership buy-in to get full support and resources to implement SAIEF is a pre-requisite. Without this support SAIEF implementation projects would fail or end up being an ethics theater.
The following cybersecurity concepts and controls have been selected for SAIEF and they were repurposed for the corresponding ethical controls.
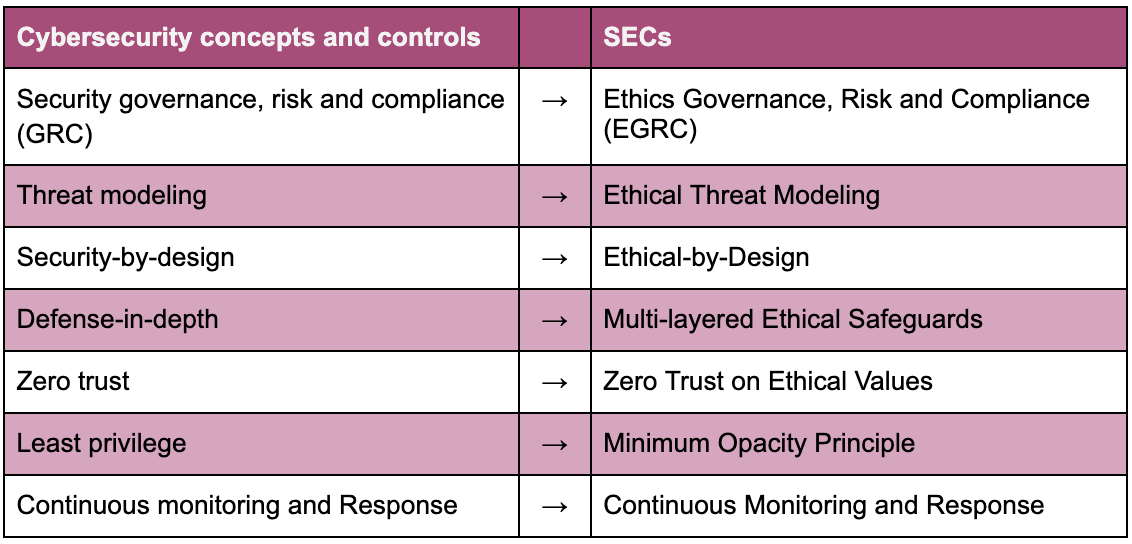
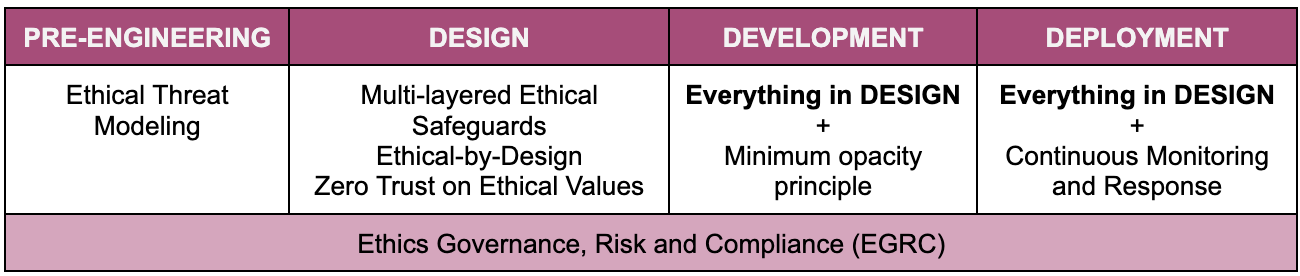
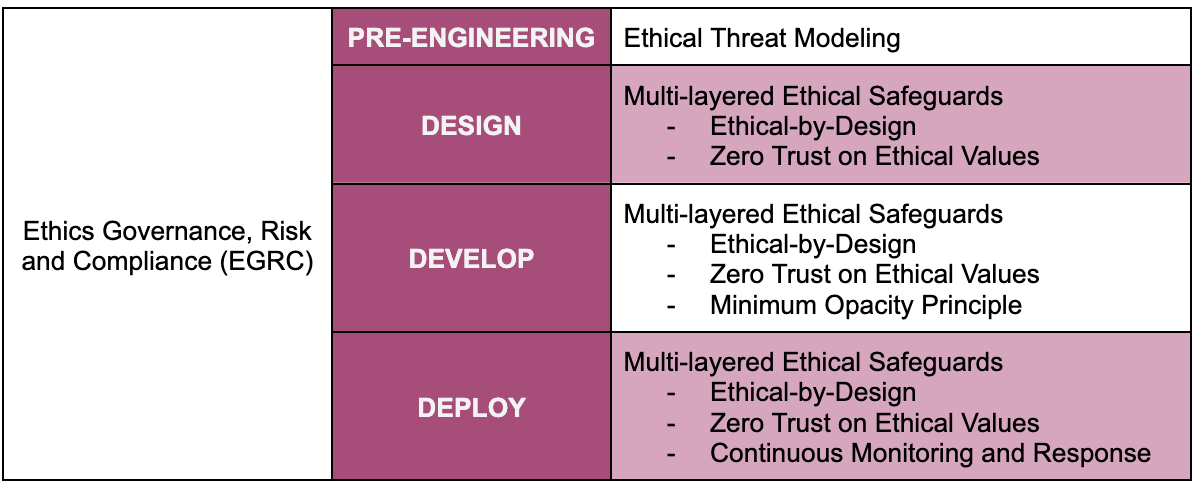
SAIEF can be extended with additional cybersecurity concepts and controls not covered in this framework (i.e. Top 18 security controls by Center for Internet Security). SAIEF is structured around common AI engineering phases: Design, Development, and Deployment. Some SECs such as Ethics Governance, Risk and Compliance (EGRC) are applicable throughout the engineering process as a core element. Similarly some concepts such as multi-layered ethical safeguards apply across multiple phases.
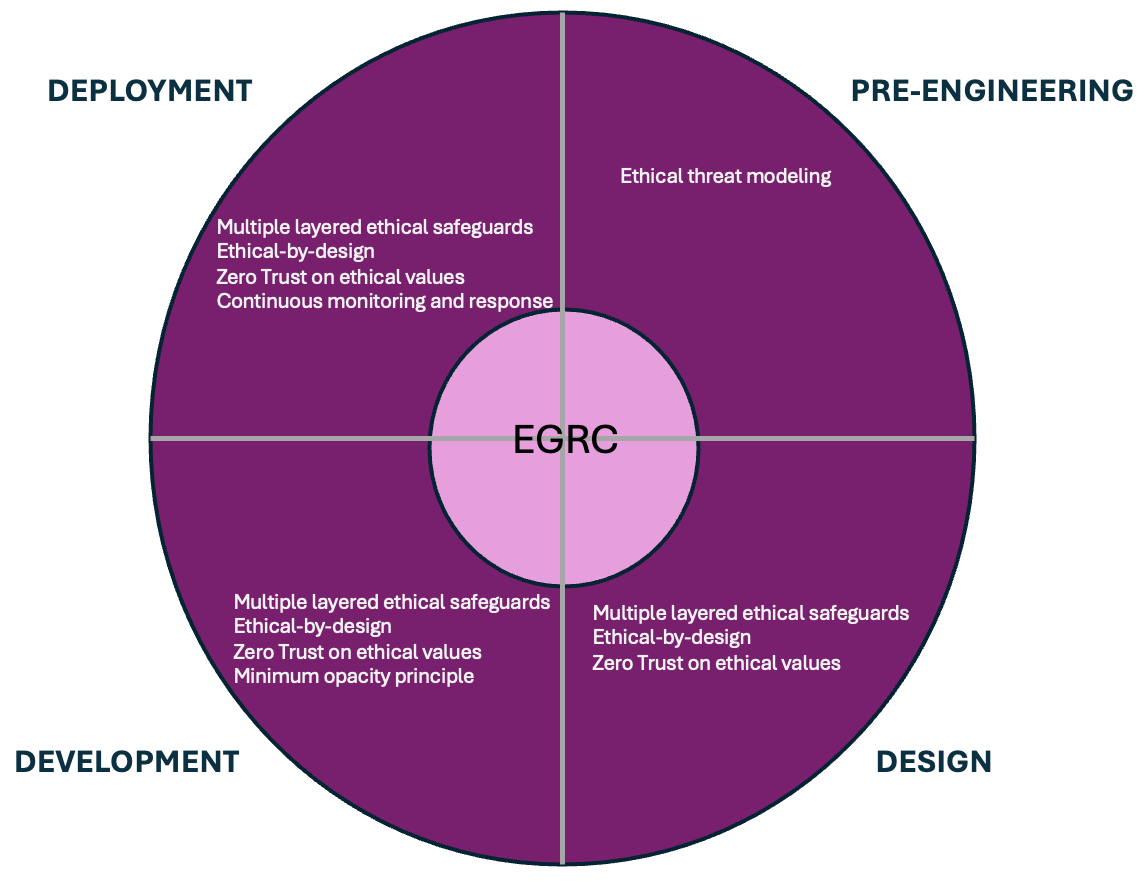
Below is another way to visualize the framework as the AI engineering process is continuous.
Security-informed Ethical Controls (SECs)
1. Ethics Governance, Risk and Compliance (EGRC)
Security principle: A holistic approach that helps organizations align their security, risk management, and compliance efforts with their overall business goals.
AI ethics translation: Establish formal decision-making structures, norms, risk management processes, metrics, and a compliance program with participation from all stakeholders to holistically oversee ethics in products and in an organization.
Implementation process:
Form or leverage an existing formal governance body consisting of diverse stakeholders
Publish policies and standards to cover the OECD AI value-based principles
Develop a stakeholder engagement policy and engage stakeholders throughout the AI engineering process
Assess and treat risks to ethical values (i.e. fairness, transparency, privacy)
Define, track, and report metrics on various desired ethics outcomes
Select a compliance framework, and align, and monitor compliance to it
Practical tools:
An ethics steering committee to oversee ethics in an organization
A GRC tool that provides a policy library, risk management and remediation, metrics data collection and tracking and compliance management and remediation functions
An ethics risk assessment framework
2. Ethical Threat Modeling
Security principle: Threat modeling is a proactive multi-stakeholder exercise that analyzes what security vulnerabilities could exist or which security threat could materialize to mitigate risks for a product architecture, function or feature using a framework (i.e. STRIDE)
AI ethics translation: Establish an ethical threat modeling process that is radically inclusive to identify potential violations and threats to the ethical values (fairness, transparency, etc.) in a data set, algorithm, architecture, function, feature, or use of a product.
Implementation process:
Adopt an existing or develop a custom ethical threat modeling framework to use during the exercises
Develop an ethical threat modeling process with feedback from diverse stakeholder groups
Engage all the stakeholders as per the stakeholder engagement policy
Train facilitators to run ethical threat modeling exercises based on the framework and the process.
Train all relevant stakeholders on the framework and the process.
Inject ethical threat modeling into the beginning of the product design and development processes or merge it into the security threat modeling process
Develop and use a tracking mechanism to monitor remediation of the identified potential violations and threats
Practical tools:
An ethical threat modeling framework
Hybrid (in-person and remote) sessions
A threat modeling tool to annotate threats and related information
A tool to document and track identified violations and threats (i.e. issue management tools used in product development)
3. Ethical-by-Design
Security principle: Security-by-design indicates a concept where protection of systems and data of a technology product is considered and built-in at the very early design phase of a product development lifecycle.
AI ethics translation: Adopt and exercise the Ethical-by-Design principle to sow ethical values (i.e. fairness, transparency) into an AI system from its initial design onwards.
Integration into the Development Lifecycle:
Planning:
Set ethical goals and high-level ethical requirements for the system
Engage all the stakeholders throughout as per the stakeholder engagement policy
Consider all different definitions of an ethical value (i.e. fairness) that are relevant to the use case at hand, and select the most appropriate one based on stakeholder input
Analysis:
Gather detailed ethical requirements from diverse set of stakeholders to the system
Define the acceptance criteria for the identified ethical goals
Design:
Perform an ethical threat modeling exercise with all the stakeholders
Design an architecture that enables satisfying the ethical requirements
Consider ethical values in all design decisions, such as training data curation (i.e. fairness, privacy), model design (i.e. accountability), interface design (i.e. transparency), etc.
Data collection and selection
Acquire datasets that are validated as void of any ethical issues
Scan the training data for any ethical issues
Algorithm and feature development:
Select the most ethically appropriate algorithm (i.e. free of algorithmic bias)
Build features for the ethical values (i.e. UX design for transparency)
Build features with the ethical values (i.e. use of fairness-aware learning algorithms)
Train the AI system for expected and unexpected/adversarial ethical outputs or behaviors
Testing:
Perform unit tests for the ethical values
Conduct User Acceptance Tests (UAT) by a diverse set of stakeholders to verify that the AI system meets the acceptance criteria for the ethical values (i.e. fairness, transparency, etc.)
Model deployment and operationalization:
Ethical-by-default with ethically conservative parameters are selected by default
Ensure that deployment itself follows the ethical values (i.e. accessibility to the entire target user base or deployment with minimal environmental harm)
Continuously evaluate AI system performance to ensure the system behaviors or outputs consistently reflect the ethical values it was developed with and trained on
4. Multi-layered Ethical Safeguards
Security principle: Defense-in-depth is a cybersecurity concept that recommends the implementation of multiple layers of safeguards or controls so that if one of them failed, attackers would still need to beat the subsequent controls in order to compromise the security properties of a protected resource.
AI ethics translation: Implement multiple layers of controls to protect the ethical values (i.e. fairness, transparency) and prevent a control from becoming a single point of failure causing ethical values to be degraded or violated.
For example, the sample layers of controls to protect against the violation of fairness across the AI development and deployment lifecycle are:
Layer 1: Data collection and selection
Documenting data lineage to establish data provenance
Performing 3rd party risk assessment (if data is acquired from a 3rd party)
Periodic scanning data anomalies to identify any data drift or change in data distribution
Layer 2: Algorithm design and development
Strong access controls to model source code and weights (assumes closed models)
Incorporating fairness metrics into model optimization
Adversarial training simulating unfair decisions
Layer 3: Model deployment and operationalization
Allowing equal/fair access to users based on demographic parity.
Continuous monitoring for unfair model output such as fairness metrics
A response process to triage any alerts indicating unfair (unethical, in general) behavior
Layer 4: Human oversight and appeal mechanisms
For high-consequence decisions (including fairness), require human validation
Human review of any continuous monitoring alerts indicating unfair (unethical, in general) behavior
For end-user complaints about unethical behavior (including fairness), have a reporting process that is easy to submit and with a quick turnaround.
5. Zero Trust on Ethical Values
Security principle: Zero-trust is a cybersecurity concept whose core principle is “never trust, always verify” and it assumes that no user, device, or application and their interactions should be trusted.
AI ethics translation: Never trust that the ethical values in an AI system will always be maintained or assume that they will be sustained. Assume the presence of ethical issues throughout the entire AI development and deployment lifecycle from training data collection, through model development, learning, deployment and beyond. Always verify the inputs (i.e. prompts), the weights, the decision-making process (i.e. mechanistic interpretability, saliency maps), outputs (classifications and regression outcomes) and quickly respond to any ethical issues that arise from them.
Data collection and selection:
Continuous verification of:
Ethical risks from the training data vendor
Ethical violations in the data
Quick mitigation of any causes of ethical violations in the training data set
Algorithm design and development:
Oversee and analyze all training iterations and phases such as pre‑finetuning. mid-training, supervised fine-tuning, preference fine-tuning (RLHF) and post‑training (i.e. RLVR or Reinforcement Learning with Verifiable Rewards) for any ethical issues
Adversarial training for ethical values
Use methods to map out the entire chain of reasoning throughout the neural network layers and adjust components to approximate to the desired ethical KPIs
Build transparency (including explainability and interpretability) with appropriate opacity to provide useful and actionable feedback to the developers
Model deployment and operationalization:
Continuous monitoring of:
User interactions (assume adversarial interactions)
Inputs and generative AI prompts
Outputs (assume existing and emergent ethical violations)
Dynamic policy enforcement for detected drifts from built-in ethical values
Rapid response to any ethical violations detected or reported
6. Minimum Opacity Principle
Security principle: The least-privilege principle states that a system account must only have the minimum necessary privileges required to carry out its assigned role.
AI ethics translation: An AI system must provide for the minimum opacity to become as transparent as possible to be clear and understandable to its users while protecting against misuse.
Implementation approach:
Perform a transparency audit to determine what users must know vs what they can know
Analyze the stakeholder needs for transparency
Identify and mitigate the risks emanating from providing more than the required level of transparency
Implement role-based or layered transparency: Have different layers of transparency based on the stakeholders’ needs and capabilities
Test the transparency levels to ensure there is a balance between transparency and security/privacy
Practical controls:
Collect and train the model with user feedback for the usefulness of the offered reasoning or explanations
Analyze each transparency output to ensure that the offered reasonings and explanations do not divulge information decided to remain opaque
Detect and respond to any brute-force attempts for gathering information about the inner-workings of the model
7. Continuous Monitoring and Response
Security principle: Detecting suspicious activities by continuously looking for patterns in aggregated logs from different systems and responding to neutralize them.
AI ethics translation: Real-time monitoring of ethical performance of AI systems and rapid response to correct any degradation and deviation from their instilled ethical values.
Monitoring processes
Define Key Performance Indicators (KPI) for desired performance for each ethical value (e.g. fairness metrics, bias indicators, transparency scores)
Live ethical performance data collection to calculate the defined KPIs
Dashboard to visualize live ethical KPIs
Alerting on detected ethical drifts
Implement issue reporting mechanisms for users
Response processes
Implement dynamic ethical policy enforcement for detected drifts or deviations
Develop an ethical incident response plan and step-by-step playbooks
Provide mechanisms for stakeholders to report any ethical incidents they experience
Assemble an ethical incident response team
Train the team and conduct periodic ethical incident response exercises
Classify and assign severity to ethical incidents
Respond (analyze, contain, mitigate) to and recover from ethical incidents based on the plan and the playbooks
Communicate the detected incidents to the stakeholders
Perform lessons-learned sessions to continuously improve the ethical incident response capabilities
How to implement SAIEF
The implementation of SAIEF has a pre-requisite of senior management support. It is assumed that the senior management embraces AI ethics and fully supports the implementation of SAIEF. Once that pre-requisite is in place, SAIEF can be implemented by taking the following steps in order:
Step 1: Establish the Ethical Governance, Risk, and Compliance (EGRC) program
Step 2: Analyze the threats to the ethical values in the proposed solution using Ethical Threat Modeling
Step 3: Implement Multi-Layered Ethical Safeguards throughout the AI engineering lifecycle
Ethical-by-Design
Zero trust on ethical values
Minimum opacity principle
Continuous monitoring and response
The EGRC program is the foundation of the framework and it must be built as a pre-requisite spanning from the initial concept or research question through development, deployment, and beyond. The EGRC helps define the problem statement, which considers what kind of ethical principles are mandatory for the system to fulfill, what kind of data are to be used, how the outcomes are measured, and what is optimized (objective function) in the system. It must also enable to engage all the stakeholders and keep them engaged throughout the AI engineering lifecycle as well.
Once the EGRC foundation has been built, the project team comprised of representatives from all stakeholder groups must perform an Ethical Threat Modeling session to analyze the threats to ethical values in the proposed solution. This step is key to surface early any ethical issues such as bias, opacity, or private data disclosure and plan to address them.
After the threats to ethical values have been identified the AI engineering lifecycle can commence. This is where Multi-layered Ethical Safeguards can be started to be built. These controls span throughout the AI engineering lifecycle.
The team must start with Ethical-by-Design to ensure ethics is built into the development practices, data collection, algorithm development, training, testing and deployment. Ethics training and ethical coding practices must be provided to all the project teams.
Followed by the ethical-by-design implementation, Zero Trust on Ethical Values is implemented which goes throughout the AI engineering lifecycle This control may include multiple safeguards that continuously verify all resources and components used such as the training data, the algorithm, the users, etc.
One of the multi-layered ethical safeguards is the Minimum Opacity Principle that enables an appropriate level of transparency without introducing any security or privacy risks.
Finally, when the proposed solution has been developed and deployed, the entire system must be continuously monitored for ethical issues. Continuous Monitoring and Response can be the last safeguard to monitor the system and its decisions or outputs for any ethical issues and quickly fix them.
The diagram below depicts the narrated implementation steps above.
Strengths and Limitations
The following strengths make SAIEF a compelling methodology for consideration:
Grounded in reality: SAIEF is based on widely-known, tried and tested cybersecurity concepts practiced in the field.
Based on credible research: Based on recent academic research and trends
Applied to a real case: Justifies its benefits by demonstrating how it could have been useful in a real case
The following limitations will need to be considered and further addressed:
Time limit: The current version of SAIEF was developed in only four weeks
Needs real testing: SAIEF must be applied to a currently ongoing AI system development project
Non-exhaustive list of SECs: The group of SECs included in the current version of SAIEF is not an exhaustive list. It is only a small sample from security concepts and controls practiced in cybersecurity.
Limited specificity: The SECs require more specificity to be more useful to the practitioners on the ground, such as how to perform a transparency audit to determine the level of transparency vs opacity.
Lack of metrics: Metrics that indicate if SAIEF is successful in reducing ethical risks have to be developed.
Conclusion
SAIEF is just one of the attempts of intervention to strengthen AI ethics implementation by detecting and preventing violations of ethical principles. What makes it noteworthy is its use of the teachings of cybersecurity given the symbiotic relationship between ethics and cybersecurity, effectively breaking the long standing silos between the two disciplines.
SAIEF aims to demonstrate that cybersecurity and ethics have a lot in parallel. Just like governing and creating a culture of cybersecurity, organizations must do the same for ethics. Security threat modeling can be borrowed to identify and analyze how the defined ethical principles could be violated and how they could be withstood. Secure-by-design can be adopted to instill ethics throughout the design, development, deployment, and use of an AI system. Defense-in-depth can be applied as multi-layered ethical safeguards to prevent the single point of failure of one safeguard causing ethics incidents. Organizations can transfer the teaching of the zero-trust framework to ethics where they never blindly assume or trust continued ethical behavior of an AI system. Zero-trust is enabled by continuous monitoring for ethical violations and rapidly responding (manually or automatic) to correct them as soon as possible. The concept of least privilege can be inverted as minimum opacity to ensure AI systems can be transparent and share reasoning of outcomes as much as possible without jeopardizing privacy and security. Many more cybersecurity teaching could be borrowed to expand SAIEF.
Next steps for SAIEF include definition of Critical Success Factors (CSF) and Key Performance Indicators (KPIs). Using those metrics, SAIEF needs to be field-tested at a few current AI development projects to prove its claimed effectiveness.
SAIEF turns ethics into an engineering problem that cybersecurity practitioners would appreciate given their hands-on, practical nature. Cybersecurity practitioners are uniquely positioned to contribute to ethics, because they have the necessary traits and skills such as managing risks in socio-technical and complex systems that perfectly match the attributes needed to ensure engineering ethics into AI. As a result, SAIEF allows cybersecurity and ethics practitioners, once thought as separate professions, to team up and collaborate to become a force to uphold ethical values in AI to reap its immense benefits while protecting individuals, communities, the society at large, and the planet; just like cybersecurity.
Appendix A: Application example of SAIEF
Now that we understand SAIEF, here is an example about how it can be implemented based on a well-known case study. The goal is to
perform a look-back on the selected case study and show that if SAIEF had been in place, how the outcomes could have been different.
give an example to the practitioners about how to implement SAIEF
Introduction to the case
Optum, Inc. is an American healthcare company that provides technology services, pharmacy care services (including a pharmacy benefit manager) and various direct healthcare services. Optum was formed as a subsidiary of UnitedHealth Group in 2011 by merging UnitedHealth Group's existing pharmacy and care delivery services into the single Optum brand, comprising three main businesses: OptumHealth, OptumInsight and OptumRx
OptumHealth - Optum Health is a patient-centered care organization serving communities nationwide by enabling high-quality, fully accountable value-based care. This segment focuses on direct care delivery, including primary care, specialty care, and behavioral health services. Its revenue in 2024 was $105.4 billion.
OptumInsight - Optum Insight is partnering with payers, providers, governments and life sciences companies to simplify and enhance clinical, administrative and financial processes through software-enabled services and analytics, while advancing value-based care. Its revenue in 2024 was $18.8 billion.
OptumRx - This is Optum's pharmacy benefit management (PBM) business, providing pharmacy services and prescription drug benefits management. Its revenue in 2024 was $133.2 billion.
Optum, the largest employer of physicians in the US, now employs nearly 90,000 physicians and 40,000 advanced practice clinicians (as of late 2023). It supports 130,000 physicians, 9 out of 10 U.S. hospitals and 67,000 pharmacies with innovative solutions. At the end of 2024, Optum Health served 4.7 million people with value-based care.
Optum represents one of the largest healthcare services companies in the United States.
OptumInsights, Optum’s technology services and analytics business, launched an analytics algorithm called ImpactPro. Impact Pro is a claims-based risk stratification algorithmic tool that assigns "risk scores" for patients and flags the patients who are at high risk for specialized interventions. ImpactPro generates risk scores for patients and those above the 55th percentile are referred to their primary care physician, who is provided with contextual data about the patients and asked to consider whether they would benefit from program enrollment.
Impact Pro was found to exhibit significant racial bias: the risk scores it generated were putting white patients higher in the priority list for specialized interventions than black patients who were equally sick. Overall, of the patients identified by the algorithm as needing more care, only 18% were black. If the algorithm were to reflect the true proportion of the sickest patients, black patients would have made up about 46% of the patients identified instead. In other words, correcting the bias would more than double the number of black patients flagged as at risk of complicated medical needs within the health system.
The algorithm was designed to deliberately omit the race data with the good intention to address racial bias and was trained on cost data (i.e., dollars spent on healthcare) rather than the health and underlying physiology of the patients. The assumption that cost could be used as a proxy for health need meant that the model valued the people who historically had access to healthcare more than those people who actually needed care. Although race was excluded as a category in the model, the bias surfaced in relation to race.
The SAIEF Intervention
As noted in How to implement SAIEF, it is assumed that the SAIEF project team has full OptumInsight senior management support of AI ethics and the implementation of SAIEF.
Step 1: Establish the Ethical Governance, Risk, and Compliance (EGRC) program - Optum could have established a strong EGRC program that included representatives from all stakeholder groups to define the problem: Improve health outcomes for patients relative to the cost of achieving those outcomes.
Step 2: Analyze the threats to the ethical values in the proposed solution using Ethical Threat Modeling - Then Optum could have performed an Ethical Threat Modeling with all the stakeholders and identified the algorithmic bias by the use of healthcare expenses as a proxy to the necessary medical services. In addition, the risk of lack of transparency where no explanations were provided to users about why a patient was marked as high risk and enrolled in a specific program could have been identified
Step 3: Implement Multi-Layered Ethical Safeguards throughout the AI engineering lifecycle
Ethical-by-Design: If the list of measures listed above grouped under the Ethical-by-Design safeguard had been in place throughout the AI engineering lifecycle and beyond at Optum, the algorithmic bias could have been identified before independent researchers discovered the issue.
Zero trust on ethical values: If the list of measures listed above grouped under the Zero Trust on Ethical Values had been in place and as a result, the algorithm had not been trusted, and regularly validated during the AI engineering lifecycle, the algorithmic bias could have been detected.
Minimum opacity principle: If Impact Pro was transparent to both care providers and patients, the algorithmic bias covered in the case could have been reported by the stakeholders and remediated.
Continuous monitoring and response: If the list of measures listed above grouped under the Continuous Monitoring and Response had been in place, the algorithmic bias could have been detected and quickly triaged and fixed.
Conclusion
Bias sneaks in discreet ways and even if one had the best intentions, their model may echo existing bias or generate new biases after it is deployed even if protected data points are omitted for the sake of fairness. In high-stakes sectors like healthcare, these biases would have life-and-death impact on individuals. This is what happened with Optum’s Impact Pro model. Optum should have had a governance, risk and compliance function that embraced radical diversity as required by the nature of the healthcare sector. Upon this strong foundation, Optum could have built all the other SECs. As demonstrated above, if Optum had the SAIEF components in place and functioning effectively, there would have been a higher likelihood to detect and quickly remediate the algorithmic bias before independent researchers reported it. SAIEF could have improved quality of life for millions of individuals.
Appendix B: Tools that facilitate SAIEF implementation
Ethical Threat Modeling Worksheet
Purpose: Systematically identify potential ethical vulnerabilities in AI systems by applying cybersecurity threat modeling principles to fairness, transparency, accountability, privacy, wellbeing, and safety concerns.
When to Use
Early in the pre-engineering phase
Before algorithm deployment
During major system updates
As part of regular ethical risk assessments
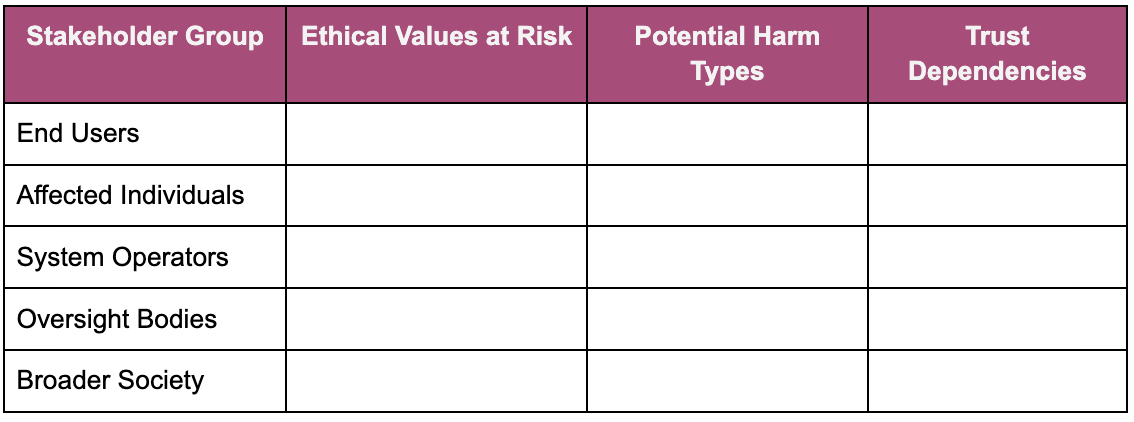
Step 1: System Context & Stakeholder Analysis
AI System Profile:
System Name: ________________________________
Primary Function: ________________________________
Decision Authority Level: ☐ Advisory ☐ Semi-Automated ☐ Fully Automated
Affected Populations and groups: ________________________________
Impact Domain: ☐ Healthcare ☐ Finance ☐ Criminal Justice ☐ Employment ☐ Education ☐ Other: _______
Stakeholder Threat Surface:
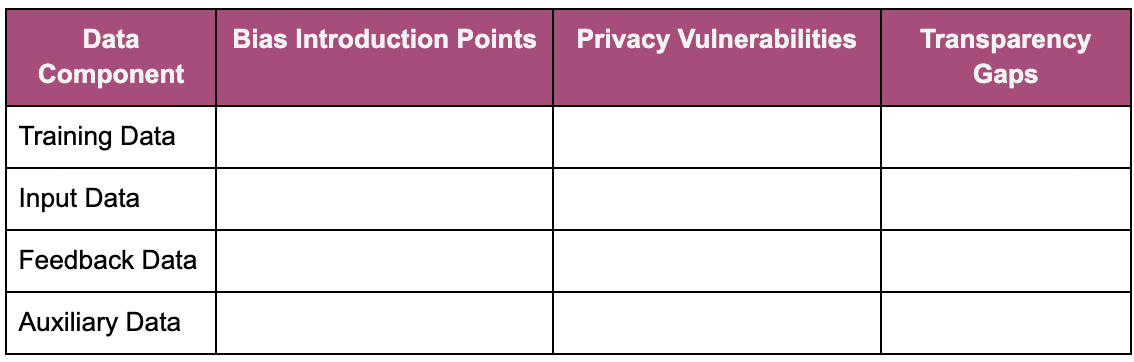
Step 2: Ethical Attack Surface Mapping
Data Attack Vectors:
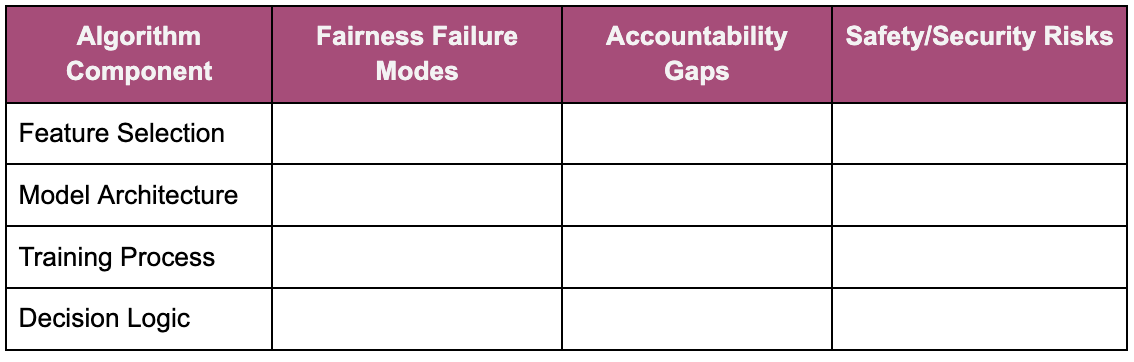
Algorithm Attack Vectors:
Interface Attack Vectors:
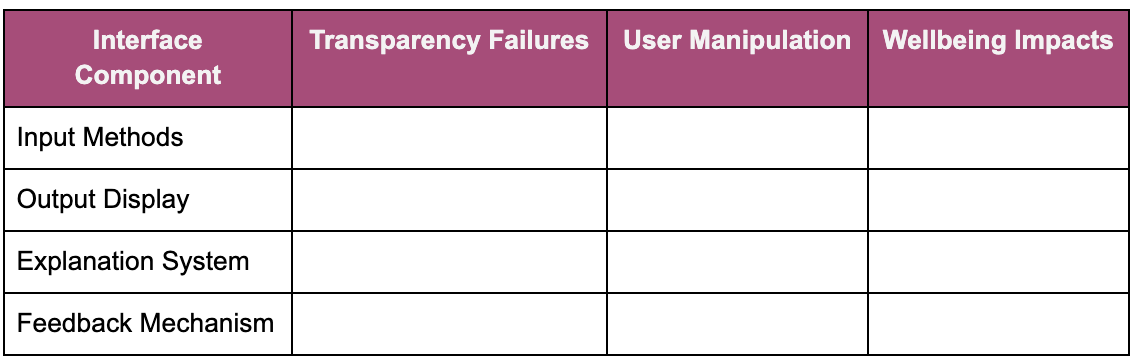
Step 3: Ethical Threat Scenario Development
FAIRNESS Threats:

TRANSPARENCY Threats:

PRIVACY Threats:

ACCOUNTABILITY Threats:

WELLBEING Threats:

SAFETY/SECURITY Threats:

Step 4: Adversarial Ethical Analysis
Proxy Variable Vulnerabilities:
What seemingly neutral variables might correlate with protected characteristics?
What proxy variables could generate biased outputs?
How could historical biases be embedded in training data?
What measurement choices might systematically disadvantage certain groups?
Feedback Loop Exploitation:
How could biased outputs create self-reinforcing discrimination cycles?
What user adaptations might game the system in unethical ways?
How might system recommendations influence future data collection?
Edge Case Exploitation:
What happens when the system encounters underrepresented populations?
How does the system behave with missing or incomplete data?
What are the failure modes when multiple ethical constraints conflict?
Adversarial User Scenarios:
How might malicious users exploit the system to harm others?
What happens if users deliberately provide false or misleading information?
How could organized groups coordinate to manipulate system behavior?
Step 5: Risk Prioritization & Mitigation Planning
Risk Assessment Matrix:

Mitigation Strategy Framework:

Implementation Roadmap:
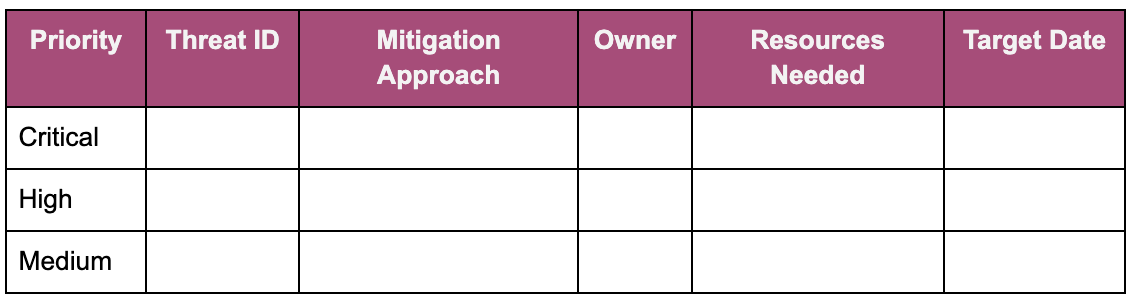
Multi-Layered Ethical Safeguards Implementation Guide
Purpose: Implement defense-in-depth ethical controls across all AI system layers, ensuring no single point of ethical failure using cybersecurity-inspired layered protection principles.
When to Use:
Early in the pre-engineering phase
Before production deployment
As part of ethical compliance audits
For continuous ethical assurance validation
Layer 1: Ethics Governance, Risk & Compliance (EGRC) Controls
Governance Structure
Ethics steering committee established with diverse stakeholder representation
Clear roles and responsibilities defined for ethical decision-making
Regular ethics review meetings scheduled and documented
Executive-level sponsorship and accountability assigned
Policy & Standards Framework
Ethical AI policies published and communicated organization-wide
Technical standards for fairness, transparency, and accountability defined
Stakeholder engagement policy published and diverse stakeholders engaged
Procurement guidelines include ethical AI requirements for vendors
Data governance policies address bias and discrimination prevention
Risk Management Process
Ethical risk assessment methodology established
Regular ethical risk reviews conducted across all AI projects
Risk appetite and tolerance levels defined for ethical considerations
Escalation procedures established for high-risk ethical issues
Compliance & Monitoring
Regulatory compliance requirements mapped and tracked
Ethical metrics and KPIs defined and monitored
Internal audit processes include ethical AI assessments
External ethical assessments and certifications pursued
Layer 2: Ethical Threat Modeling & Assessment Controls
Systematic Threat Identification
Formal ethical threat modeling process implemented
Multi-stakeholder threat identification workshops conducted
Threat scenarios documented across all ethical dimensions
Regular threat landscape updates based on emerging risks
Bias & Discrimination Analysis
Comprehensive bias assessment across protected characteristics
Intersectional analysis conducted for multiple demographic factors
Historical context analysis of training data sources
Proxy discrimination analysis for seemingly neutral variables
Adversarial Testing Framework
Red team exercises focused on ethical vulnerabilities
Edge case testing for underrepresented populations
Adversarial attacks simulated against fairness mechanisms
Game theory analysis of user manipulation scenarios
Impact Assessment Methodology
Stakeholder impact analysis conducted for all affected groups
Quantitative and qualitative harm measurement frameworks established
Long-term societal impact considerations documented
Cumulative and systemic effect analysis completed
Layer 3: Multi-Layered Ethical Safeguards Controls
Data Layer Protection
Bias detection and mitigation tools implemented in data pipelines
Data quality assessment includes fairness and representation metrics
Privacy-preserving techniques applied (differential privacy, federated learning)
Data provenance and lineage tracking systems operational
Algorithm Layer Protection
Fairness-aware machine learning algorithms implemented
Multi-objective optimization balancing accuracy and ethical metrics
Interpretable models used where transparency is required
Ensemble methods include diverse perspectives and approaches
Interface Layer Protection
User-appropriate explanation systems implemented
Confidence intervals and uncertainty clearly communicated
Human oversight and override mechanisms integrated
Accessible design principles applied across all interfaces
System Layer Protection
Circuit breaker mechanisms for ethical threshold violations
Graceful degradation procedures when ethical constraints conflict
Backup decision-making processes for system failures
Integration with existing security and compliance infrastructure
Layer 4: Ethical-by-Design Implementation Controls
Requirements & Planning Integration
Ethical requirements gathered alongside functional requirements
Stakeholder needs assessment includes ethical considerations
Success metrics defined for ethical as well as business objectives
Trade-off analysis conducted between competing ethical values
Design & Architecture Integration
Ethical considerations integrated into system architecture decisions
Privacy-by-design principles implemented throughout system design
Transparency mechanisms designed into core system functionality
Accountability mechanisms built into decision-making workflows
Development & Testing Integration
Ethical code review processes established and followed
Fairness testing integrated into continuous integration pipelines
User acceptance testing includes diverse stakeholder groups
Ethical regression testing prevents degradation of ethical performance
Deployment & Operations Integration
Ethical deployment checklists completed before go-live
Production monitoring includes real-time ethical performance metrics
Incident response procedures include ethical harm scenarios
Post-deployment ethical performance validation conducted
Layer 5: Minimum Opacity Principle Controls
Transparency Audit Framework
Stakeholder information needs assessment completed
Transparency vs. privacy vs. security trade-off analysis documented
Multi-level explanation systems designed for different user types
Information disclosure policies clearly defined and communicated
Explainable AI Implementation
Appropriate explainability techniques selected based on use case
Explanation quality validation conducted with real users
Explanation consistency and accuracy verified across scenarios
Alternative explanation methods provided for accessibility
Documentation & Communication
Algorithm cards or model documentation published and maintained
Known limitations and biases clearly disclosed
User training and education materials developed and distributed
Regular stakeholder communication about system capabilities and limitations
Transparency Governance
Information classification framework includes transparency requirements
Regular transparency audits conducted by independent parties
Transparency metrics tracked and reported to stakeholders
Continuous improvement process for transparency mechanisms
Layer 6: Continuous Monitoring & Response Controls
Real-Time Monitoring Infrastructure
Ethical performance dashboards operational with real-time data
Automated alerting systems configured for ethical threshold violations
Trend analysis and drift detection systems monitoring ethical metrics
Integration with existing IT operations and monitoring infrastructure
Performance Measurement Framework
Comprehensive ethical KPIs defined and tracked across all system functions
Baseline ethical performance established and regularly updated
Comparative analysis conducted against industry benchmarks
Regular performance reporting to executives and stakeholders
Incident Response Procedures
Ethical incident classification and escalation procedures established
Rapid response team identified and trained for ethical incidents
Communication protocols defined for stakeholder notification
Post-incident analysis and learning procedures implemented
Continuous Improvement Process
Regular model retraining incorporates updated ethical constraints
Stakeholder feedback collection and analysis systems operational
Lessons learned processes capture and share ethical insights
External benchmarking and best practice adoption programs active
Layer 7: Zero Trust Ethical Verification Controls
Continuous Verification Framework
Never-trust approach applied to all ethical assertions and claims
Independent verification of ethical performance claims conducted
Regular third-party ethical audits scheduled and completed
Peer review processes established for ethical design decisions
Input & Process Validation
All training data continuously validated for bias and quality
Algorithm decision-making processes regularly audited for ethical compliance
User inputs validated for potential manipulation or gaming attempts
Feature importance and model behavior continuously analyzed
Output & Impact Verification
All system outputs validated against ethical criteria before delivery
Real-world impact assessment conducted through outcome tracking
User experience validation includes ethical satisfaction measures
Long-term societal impact monitoring and assessment programs active
Dynamic Policy Enforcement
Adaptive ethical policies that adjust based on detected issues
Automated policy enforcement mechanisms integrated into system operations
Real-time ethical constraint adjustment based on performance monitoring
Emergency ethical override procedures tested and ready for activation
Implementation Assessment & Scoring
Layer Completeness Evaluation:
Layer 1 (EGRC): ___/17 controls implemented
Layer 2 (Threat Modeling): ___/16 controls implemented
Layer 3 (Multi-layered Safeguards): ___/16 controls implemented
Layer 4 (Ethical-by-Design): ___/16 controls implemented
Layer 5 (Minimum Opacity): ___/16 controls implemented
Layer 6 (Continuous Monitoring): ___/16 controls implemented
Layer 7 (Zero Trust): ___/16 controls implemented
Overall Ethical Maturity Assessment:
Level 1 - Basic (0-25%): Minimal ethical controls, high risk
Level 2 - Developing (26-50%): Some controls in place, moderate risk
Level 3 - Defined (51-75%): Systematic approach emerging, manageable risk
Level 4 - Managed (76-90%): Comprehensive controls, low risk
Level 5 - Optimizing (91-100%): Industry leading, continuous improvement
Priority Action Plan:
Immediate (0-30 days): _________________________________
Short-term (1-3 months): _________________________________
Medium-term (3-12 months): _________________________________
Long-term (12 -24 months): _________________________________